Argumentation Mining
The task of argumenation mining involves identifying the different aspects of the argumentation structure of a text, i.e. finding the central claim of a text, supporting reasons, possible objections and counters to those objections. For us, the overall goal is to integrate the different argumentative elements and relations in a global argumentation structure spanning over the whole text. (For many practical purposes, though, only certain subtasks are needed.)
A variety of applications involving automatic text processing can profit from access to the argumentative structure of text, such as: the retrieval of relevant court decisions from legal databases, the analysis of scientific papers in biomedical text mining, automatic document summarization systems, essay scoring systems, as well as opinion mining applications, not only for commercial purposes, but also as a tool for assessing public opinion in political decision-making. To make argumentation structures available for these applications, robust automatic argument recognition is required, based on resources that have been created in a reproducible fashion with a coding scheme that can be reliably applied.
Argumentation Structure and its Parsing
The argumentation structure of a text is a graph representation of the argumentative relations between the propositions expressed in the segments of the text (i.e. typically sentences or clauses). It identifies the central claim of the text, supporting premises, possible objections and counters to these objections.
We devised a scheme for annotating such argumentation structures (Peldszus Stede 2013), built a corpus annotated with those structures (see below) and worked on the automatic recognition of the structures via joint optimization (Peldszus/Stede 2015, Afantenos et al. 2018).
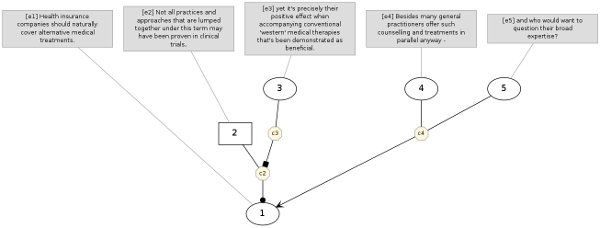
Fig. 1: An example argumentation structure
Semi-automatic Analysis of Arguments in Social Media
To find recurring arguments in debates on a certain issue, we have constructed a tool with which computer-assisted argument extraction from large text collections can be carried out. The tool (i) automatically selects a subset of the text collection that contains re-occurring topics, to minimise the amount of text that the human coder has to read, and (ii) presents selected texts and extracted information in a graphical user interface that facilitates manual coding of arguments. A video demo of the tool can be found here.
Argument Synthesis
In collaboration with colleagues in Weimar, we started work on re-synthesizing new argumentative text, using the microtexts pertaining to a common topic as input. Our first step was a human annotation study, presented in (Wachsmuth et al. 2018), followed by initial automatic experiments (El Baff et al. 2019).
Related Resources
We distribute a corpus of short argumentative texts (parallel in English and German; annotated according to the scheme mentioned above). The corpus has also been annotated with other layers of linguistic information, as explained on the corpus page.
Further, we offer the annotation tool that has been used for building the argumentation structure graphs in the microtext corpus: (GraPAT).
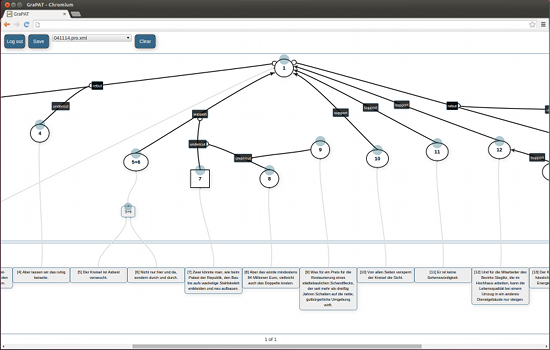
Fig. 2: Annotating argumentation structure in GraPAT
- arg-microtexts: A German English parallel corpus of short argumentative texts annotated with argumentation structures
- GraPAT: A graph-based, web-based annotation tool suited for sentiment and argumentation structure annotation
Related publications:
- Mackwyn Quadras, Manfred Stede, and Henning Wachsmuth. Assessing the Persuasive Effect of AI-Generated Image Support of Arguments. In Proceedings of the Coference on Language Resources and Evaluation (LREC). Palma de Mallorca, 2026. to appear. [Bibtex]
- Robin Schaefer. On Integrating LLMs Into an Argument Annotation Workflow. In Proceedings of the 12th Argument Mining Workshop at ACL. Vienna, 2025. [Bibtex] [PDF]
- Robin Schaefer, Sophia Rauh, and Manfred Stede. On Complex Argumentation Structure in Tweets. Argumentation et Analyse du Discours, 2025. [Bibtex] [DOI]
- Mohammad Yeghaneh Abkenar, Weixing Wang, Hendrik Graupner, and Manfred Stede. Assessing Open-Weight Large Language Models on Argumentation Mining Subtasks. In Proceedings of the Swiss Text Analytics Conference. Zurich, 2025. (to appear). [Bibtex]
- Xiaoyu Bai and Manfred Stede. Predicting Functional Content Zones in German Source-Dependent Argumentative Essays: Experiments on a Novel Dataset. In Proceedings of the 21t Conference on Natural Language Processing (KONVENS 2025). Hildesheim, 2025. [Bibtex] [PDF]
- Maria Poiaganova and Manfred Stede. From Debates to Diplomacy: Argument Mining Across Political Registers. In Proceedings of the 12th Argument Mining Workshop at ACL. Vienna, 2025. [Bibtex] [PDF]
- Mohammad Yeghaneh Abkenar and Manfred Stede. Neural mining of persian short argumentative texts. In Proceedings of the 2nd Workshop on Resources and Technologies for Indigenous, Endangered and Lesser-resourced Languages in Eurasia (LREC - EURALI). Turin, Italy, May 2024. [Bibtex] [PDF]
- René Knaebel, Robin Schaefer, and Manfred Stede. The Impact of Argument Arrangement on Essay Scoring. In Proceedings of the 1st International Conference on Recent Advances in Robust Argumentation Machines (RATIO-24). Bielefeld, 2024. [Bibtex] [PDF]
- Robin Schaefer, René Knaebel, and Manfred Stede. Towards Fine-Grained Argumentation Strategy Analysis in Persuasive Essays. In Milad Alshomary, Chung-Chi Chen, Smaranda Muresan, Joonsuk Park, and Julia Romberg, editors, Proceedings of the 10th Workshop on Argument Mining, 76–88. Singapore, December 2023. Association for Computational Linguistics. [Bibtex] [PDF]
- Robin Schaefer and Manfred Stede. GerCCT: An Annotated Corpus for Mining Arguments in German Tweets on Climate Change. In Proceedings of the 13th Language Resources and Evaluation Conference (LREC). Marseille, France, 2022. European Language Resources Association. [Bibtex] [PDF]
- Robin Schaefer, René Knaebel, and Manfred Stede. On Selecting Training Corpora for Cross-Domain Claim Detection. In Proceedings of the 9th Workshop on Argument Mining (COLING), 181–186. Online and in Gyeongju, Republic of Korea, 2022. International Conference on Computational Linguistics. [Bibtex] [PDF]
- Katarzyna Budzynska, Chris Reed, Manfred Stede, Benno Stein, and Zhang He. Framing in Communication: From Theories to Computation (Dagstuhl Seminar 22131). Dagstuhl Reports, 12(3):117–140, 2022. URL: https://drops.dagstuhl.de/opus/volltexte/2022/17271. [Bibtex] [DOI]
- Neslihan Iskender, Robin Schaefer, Tim Polzehl, and Sebastian Möller. Argument Mining in Tweets: Comparing Crowd and Expert Annotations for Automated Claim and Evidence Detection. In H. Horacek E. Métais, F. Meziane and E. Kapetanios, editors, Natural Language Processing and Information Systems (NLDB), Lecture Notes in Computer Science. Springer, Saarbrücken, Germany, 2021. [Bibtex] [DOI]
- R. Agarwal, A. Koniaev, and R. Schaefer. Exploring Argument Retrieval for Controversial Questions Using Retrieve and Re-rank Pipelines. In Working Notes of CLEF 2021 -Conference and Labs of the Evaluation Forum, CEUR Workshop Proceedings, CLEF and CEUR-WS.org. CEUR-WS.org, 2021. [Bibtex] [PDF]
- R. Schaefer and M. Stede. Argument Mining on Twitter: A survey. it - information technology, 63(1):45–58, 2021. URL: https://doi.org/10.1515/itit-2020-0053. [Bibtex]
- Mohammad Yeghaneh Abkenar, Manfred Stede, and Stephan Oepen. Neural Argumentation Mining on Essays and Microtexts with Contextualized Word Embeddings. In Proceedings of the 6th Swiss Text Analytics Conference. 2021. [Bibtex] [PDF]
- Robin Schaefer. Building an argument mining pipeline for tweets. In Online Handbook of Argumentation for AI: Volume 2. 2021. URL: https://arxiv.org/pdf/2106.10832.pdf, arXiv:2106.10832. [Bibtex]
- R. Schaefer and M. Stede. UPAppliedCL at GermEval 2021: Identifying Fact-Claiming and Engaging Facebook Comments Using Transformers. In Proc. of the GermEval2021 "Toxic" at KONVENS. Düsseldorf, 2021. [Bibtex] [PDF]
- Robin Schäfer and Manfred Stede. Annotation and detection of arguments in tweets. In Proceedings of the 7th Workshop on Argument Mining, 53–58. Online, December 2020. Association for Computational Linguistics. [Bibtex] [PDF]
- Manfred Stede. Automatic argumentation mining and the role of stance and sentiment. Journal of Argumentation in Context, 9(1):19–41, 2020. [Bibtex] [DOI]
- Ivan Namor, Pietro Totis, Samuele Garda, and Manfred Stede. Mining Italian short argumentative texts. In Proc. of the Italian Conference on Computational Linguistics (CLiC-it 2019). 2019. [Bibtex] [PDF]
- Freya Hewett, Roshan Prakash Rane, Nina Harlacher, and Manfred Stede. The utility of discourse parsing features for predicting argumentation structure. In Proc. of the 6th Workshop on Argument Mining at ACL. Florence, Italy, 2019. [Bibtex] [PDF]
- Roxanne El Baff, Henning Wachsmuth, Khalid Al-Khatib, Manfred Stede, and Benno Stein. Computational Argumentation Synthesis as a Language Modeling Task. In Proc. of the 12th Int'l Conference on Natural Language Generation. Tokyo, 2019. [Bibtex] [PDF]
- Maria Skeppstedt, Andreas Kerren, and Manfred Stede. Finding Reasons for Vaccination Hesitancy: Evaluating Semi-Automatic Coding of Internet Discussion Forums. In Proc. of MEDINFO. Lyon, 2019. URL: https://www.ncbi.nlm.nih.gov/pubmed/31437943. [Bibtex]
- Elena Musi, Mark Aakhus, Smaranda Muresan, Andrea Rocci, and Manfred Stede. From theory to practice: the annotation of argument schemes. In Argumentation and Inference - Proc. of the 2nd European Conference on Argumentation, Fribourg, 2017. College Publications, London, 2018. [Bibtex]
- Maria Skeppstedt, Andreas Peldszus, and Manfred Stede. More or less controlled elicitation of argumentative text: enlarging a microtext corpus via crowdsourcing. In Proceedings of the 5th Workshop on Argumentation Mining (at EMNLP), 155–163. Brussels, 2018. Association for Computational Linguistics. [Bibtex] [PDF]
- Elena Musi, Tariq Alhindi, Manfred Stede, Leonard Kriese, Smaranda Muresan, and Andrea Rocci. A multi-layer annotated corpus of argumentative text: from argument schemes to discourse relations. In N. Calzolari et al., editor, Proceedings of the 11h International Conference on Language Resources and Evaluation (LREC'18). Miyazaki, Japan, 2018. European Language Resources Association (ELRA). [Bibtex] [PDF]
- Henning Wachsmuth, Manfred Stede, Roxanne El Baff, Khalid Al Khatib, Maria Skeppstedt, and Benno Stein. Argumentation synthesis following rhetorical strategies. In Proceedings of the 27th International Conference on Computational Linguistics, 3753–3765. Santa Fe, New Mexico, USA, 2018. Association for Computational Linguistics. [Bibtex] [PDF]
- Stergos Afantenos, Andreas Peldszus, and Manfred Stede. Comparing decoding mechanisms for parsing argumentative structures. Argument and Computation, 9(3):177–192, 2018. [Bibtex] [DOI] [PDF]
- Maria Skeppstedt, Andreas Kerren, and Manfred Stede. Vaccine hesitancy in discussion forums : computer-assisted argument mining with topic models. In Building Continents of Knowledge in Oceans of Data : The Future of Co-Created eHealth, number 247 in Studies in Health Technology and Informatics, 366–370. IOS Press, 2018. URL: https://www.ncbi.nlm.nih.gov/pubmed/29677984. [Bibtex]
- Andreas Peldszus. Automatic recognition of argumentation structure in short monological texts doctoralthesis, Universität Potsdam, 2018. (submitted April 21, 2017; defended October 27, 2017). URL: https://nbn-resolving.org/urn:nbn:de:kobv:517-opus4-421441. [Bibtex] [PDF]
- Maria Skeppstedt, Kostiantyn Kucher, Manfred Stede, and Andreas Kerren. Topics2Themes: Computer-Assisted Argument Extraction by Visual Analysis of Important Topics. In Proceedings of the LREC Workshop on Visualization as Added Value in the Development, Use and Evaluation of Language Resources, 9–16. 2018. [Bibtex] [PDF]
- Manfred Stede and Jodi Schneider. Argumentation Mining Volume 40 of Synthesis Lectures in Human Language Technology. Morgan & Claypool, 2018. [Bibtex]
- Katarina Krüger, Anna Lukowiak, Jonathan Sonntag, and Manfred Stede. Classifying news versus opinions in newspapers: Linguistic features for domain independence. Natural Language Enginnering, 23(5):687–707, 2017. URL: http://dx.doi.org/10.1017/S1351324917000043. [Bibtex]
- Patrick Saint-Dizier and Manfred Stede. Foundations of the Language of Argumentation. Special Issue of `Argument and Computation' Volume 8(2). IOS Press, 2017. URL: http://content.iospress.com/journals/argument-and-computation/8/2. [Bibtex]
- Pietro Baroni, Thomas F. Gordon, Tatjana Scheffler, and Manfred Stede. Computational Models of Argument: Proceedings of COMMA 2016 Volume 287 of Frontiers in Artificial Intelligence and Applications. IOS Press, 2016. [Bibtex] [PDF]
- Andreas Peldszus and Manfred Stede. An annotated corpus of argumentative microtexts. In D. Mohammed and M. Lewinski, editors, Argumentation and Reasoned Action - Proc. of the 1st European Conference on Argumentation, Lisbon, 2015. College Publications, London, 2016. [Bibtex]
- K. Budzynska, M. Janier, B. Konat, J. Kang, C. Reed, P. Saint-Dizier, M. Stede, and O. Yaskorska. Automatically identifying transitions between locutions in dialogue. In D. Mohammed and M. Lewinski, editors, Argumentation and Reasoned Action - Proc. of the 1st European Conference on Argumentation, Lisbon, 2015. College Publications, London, 2016. [Bibtex]
- Manfred Stede. Toward assessing depth of argumentation. In Proceedings of COLING 2016. Osaka, Japan, 2016. [Bibtex] [PDF]
- Tatjana Scheffler and Manfred Stede. Realizing argumentative coherence relations in German: a contrastive study of newspaper editorials and Twitter posts. In Proceedings of the COMMA Workshop "Foundations of the Language of Argumentation". Potsdam, Germany, 2016. [Bibtex] [PDF]
- Andreas Peldszus and Manfred Stede. Rhetorical structure and argumentation structure in monologue text. In Proceedings of the 3rd Workshop on Argumentation Mining. Berlin, September 2016. Association for Computational Linguistics. [Bibtex] [PDF]
- Andreas Peldszus and Manfred Stede. Towards detecting counter-considerations in text. In Proceedings of the 2nd Workshop on Argumentation Mining, 104–109. Denver, CO, June 2015. Association for Computational Linguistics. [Bibtex] [PDF]
- Andreas Peldszus and Manfred Stede. Joint prediction in MST-style discourse parsing for argumentation mining. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), 938–948. Lisbon, Portugal, September 2015. Association for Computational Linguistics. [Bibtex] [PDF]
- Andreas Peldszus. Towards segment-based recognition of argumentation structure in short texts. In Proceedings of the First Workshop on Argumentation Mining, 88–97. Baltimore, Maryland, June 2014. Association for Computational Linguistics. [Bibtex] [PDF]
- K. Budzynska, M. Janier, J. Kang, C. Reed, P. Saint-Dizier, M. Stede, and O. Yakorska. Towards argument mining from dialogue. In Proc. of the Fifth Int'l Conference on Computational Models of Argument (COMMA). 2014. [Bibtex]
- Andreas Peldszus and Manfred Stede. From argument diagrams to argumentation mining in texts: a survey. International Journal of Cognitive Informatics and Natural Intelligence (IJCINI), 7(1):1–31, 2013. [Bibtex] [DOI] [PDF]
- Andreas Peldszus and Manfred Stede. Ranking the annotators: an agreement study on argumentation structure. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, 196–204. Sofia, Bulgaria, August 2013. Association for Computational Linguistics. [Bibtex] [PDF]
- Manfred Stede and Antje Sauermann. Linearization of arguments in commentary text. In Proceedings of the Workshop on Multidisciplinary Approaches to Discourse (MAD). Oslo, 2008. [Bibtex]